Introduction to no code web scraping with prowebscraper

Over the course of the web scraping series, we’ve covered a number of approaches to scraping the web. The approaches typically involved writing code using python and the various libraries that python has to offer such as BeautifulSoup, selenium and scrapy.
In this walkthrough, we’ll tackle web scraping with a radically different approach. No code data mining!
what is web scraping?
For those who may not fully understand what web scraping is, web scraping is the process of extracting information from a webpage by taking advantage of patterns in the web page’s underlying code.
We can use web scraping to gather unstructured data from the internet, process it, and store it in a structured format. This can be in form of various formats such as CSV, JSON , txt and so on.
what is prowebscraper?
Prowebscraper is an effortless, scalable web scraping tool and service that allows you to build otherwise complex web scrapers with no code at all.
To get started exploring all these goodies 😀, we’ll need to set up an account with prowebscraper, head over to their registration page and register a free account with them. Their generous free plan allows up to 1000 scraped web pages. On top of this, the prowebscraper technical and support team will guide you through your first web scraper at no extra charge in case you get stuck.
setting up our first prowebscraper
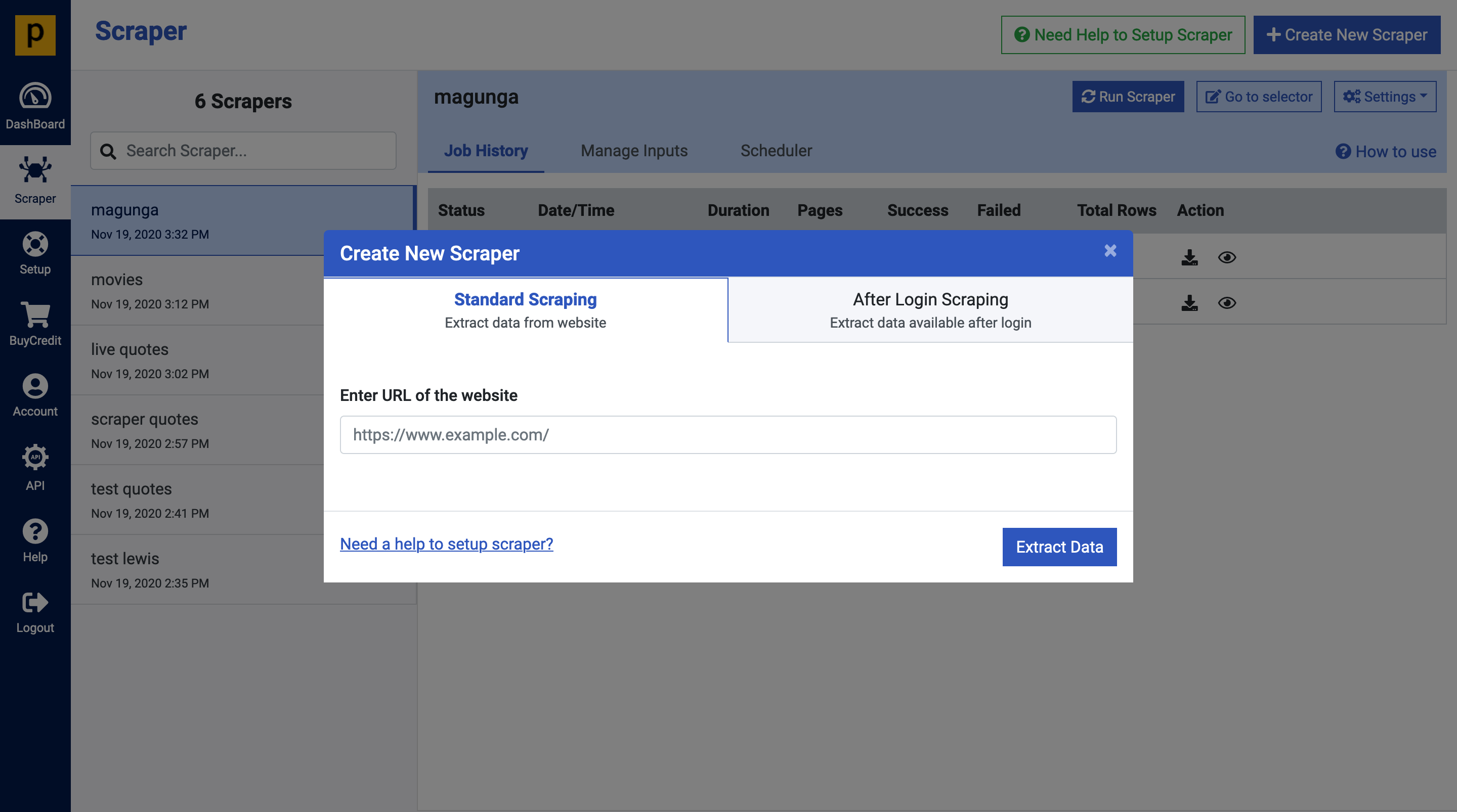
The navbar provides us with the option of creating a new scraper, choosing this will present a dialogue for configuring the scraper. Here we’ll provide any webpage url as well as any login credentials for the site should it require authentication. From the selenium post, we discovered that selenium comes in handy when we want to scrape data from javascript generated content from a webpage. That is when the data shows up after many ajax requests. Prowebscraper tackles this challenge elegantly with capability to scrape through sites with multiple levels of navigation such as pagination or content categories.
For this example we’ll use our favourite web scraping test site, quotes to scrape with javascript enabled so as to test the dynamic content extraction.
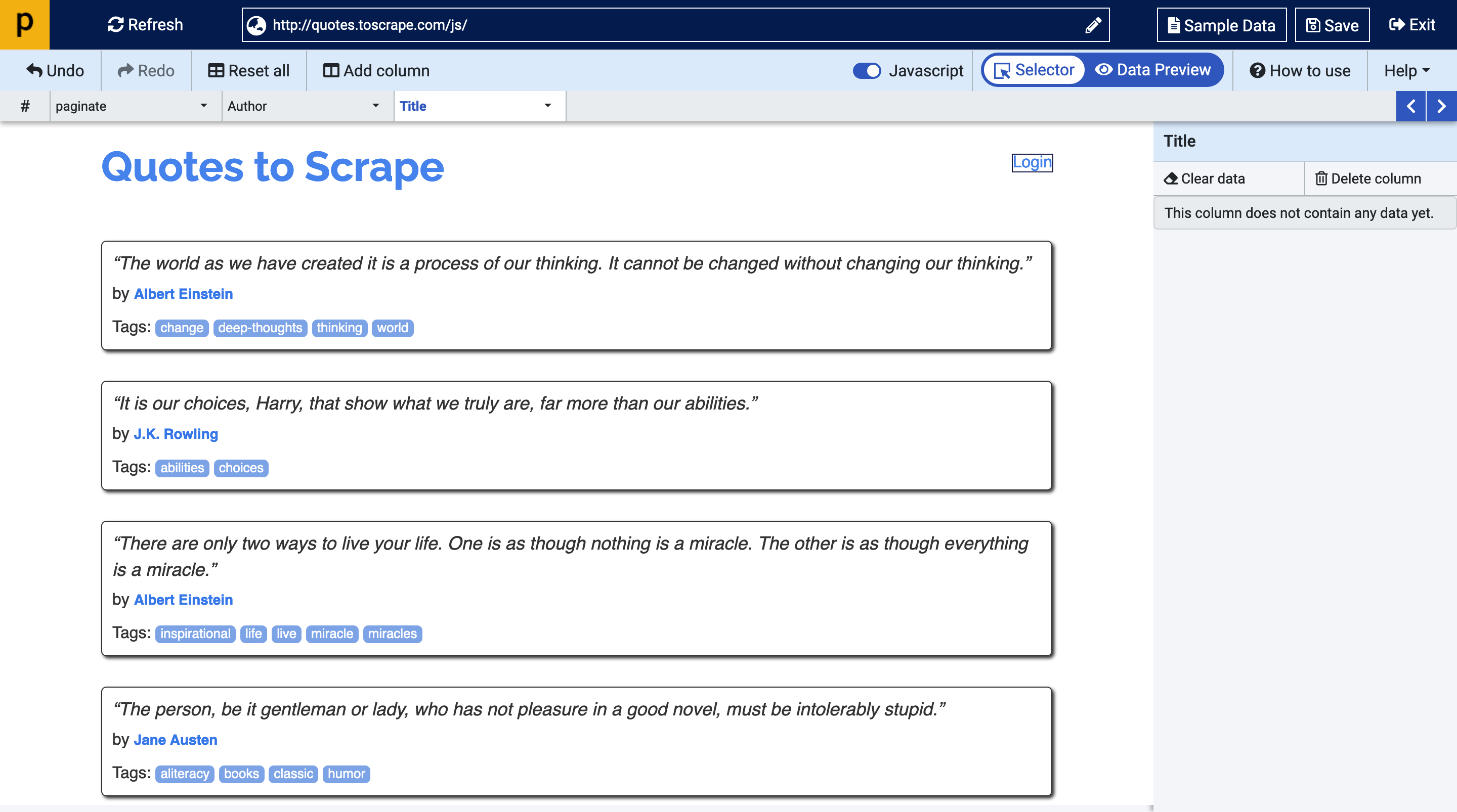
From the get-go, prowebscraper provides tooltips to get you started with your scraper. From our definition of web scraping, we identified that it’s the process of extracting information from a webpage by taking advantage of patterns in the web page’s underlying code. By hovering the mouse cursor over the HTML elements, these patterns begin to reveal themselves. Highlighted in green all over the web page. These display similar elements.
We’ll use these element to define the columns we want to extract.
For this example, the author, quote (as title from the image above) and pagination elements have been selected. These are fully customisable allowing users to name their data columns as they wish.
Running the scraper
After setting up the prowebscraper, it’s time to extract the valuable data. Prowebscraper provides a way to visualise the data before extracting the entire data. This can be done in two ways.
The first one is by switching to the data preview tab (from the image above). This will give a visual highlight of the output of the CSV file.
The second method is by hitting the sample data button. This extracts data from a single page in case your scraper has pagination enabled.
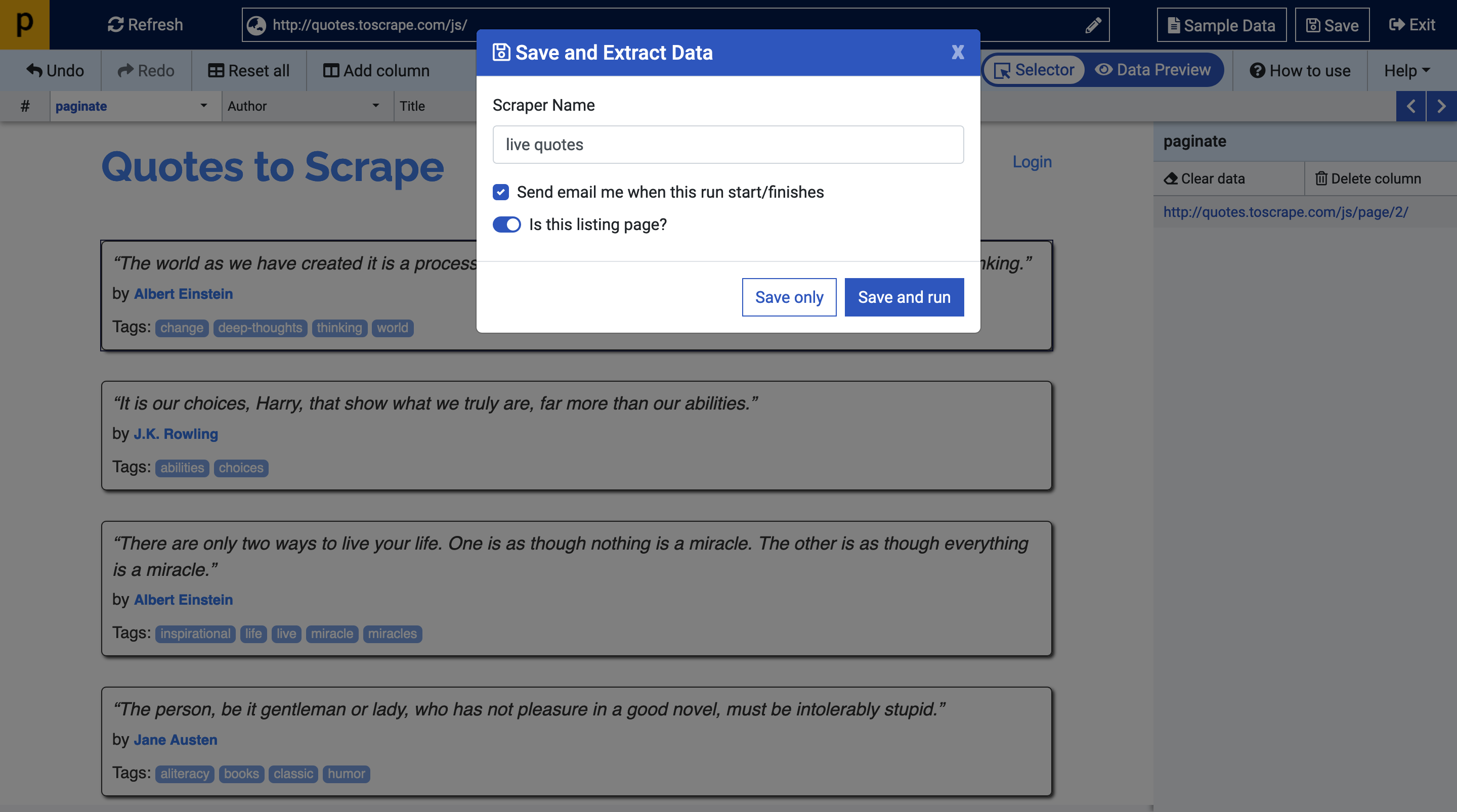
Clicking on the save button will open a dialogue that allows us to name and save the scraper for future purposes. A notification can be set up to let us know when the scraper completes its task!
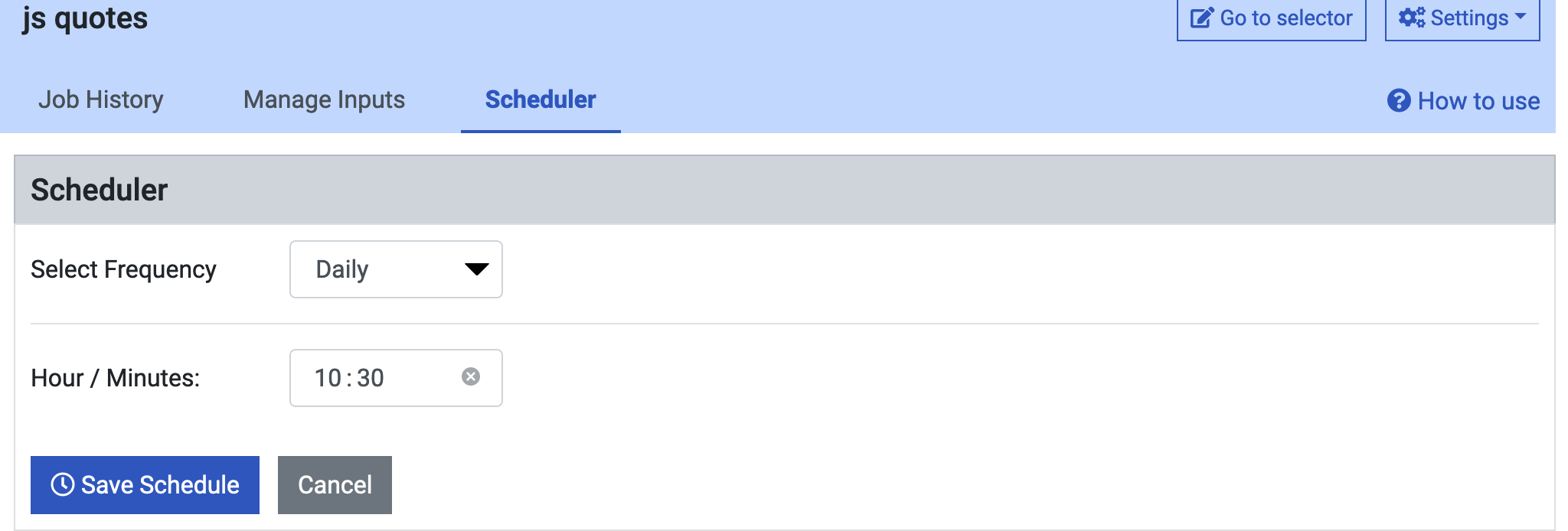
Scheduling web scraping
Bonus feature alert!
After saving the web scraper, we can schedule the web scraper to run periodically. This greatly appealed to me as It relieves me of most of the data mining tasks.
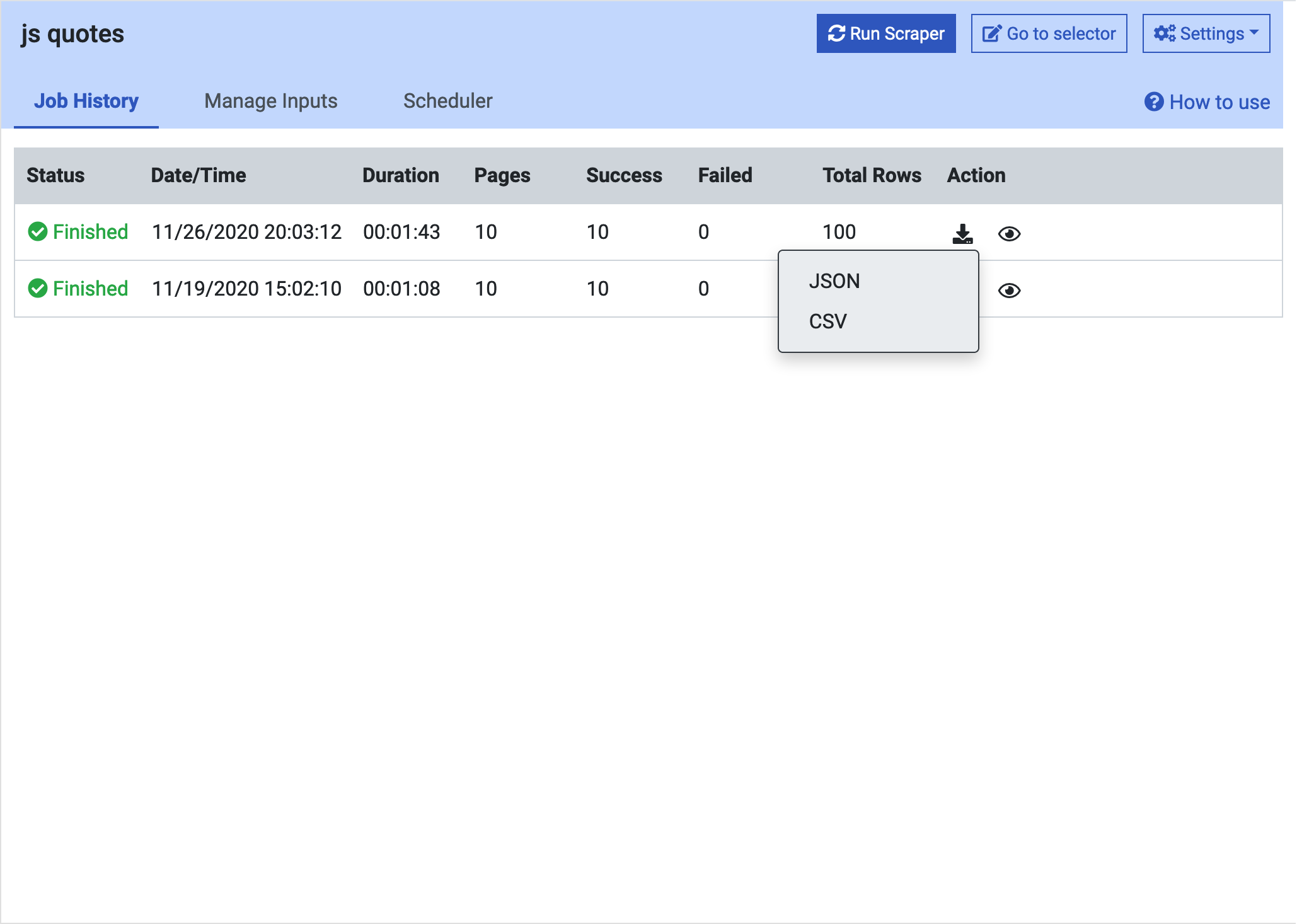
Finally we can extract data in form of JSON or CSV from our web scraper once it completes its task.
Prowebscraper can also be controlled via API. Everything that can be done through the user interface can be done with the API. For more information on the features, visit the prowebscraper features page.
That’s it from me, hopefully, now you can web scraper with this amazing tool that will improve your productivity to a whole new level. Should you have any questions, my Twitter dm is always open.
If you enjoyed this post subscribe to my newsletter to get notified whenever I write new posts or find me on Twitter for a chat.
Thanks.
More from this series
Continue reading the Web scraping techniques with python series
web scraping, Managing proxies and Captcha with scrapy and the Scraper API
How to beat CAPTCHA forms while web scraping using the scraper API.
Beginner's guide to web scraping with python's selenium
Beginner's guide to web scraping with python's selenium
Introduction to web scraping with python
An introduction to the beautiful soup python library for web scraping